Data Recipe
 Data Recipe app provides you a visual way to cleanse and prepare data for a model or some other task in a Pipeline. It also allows you to visualise data with EDA statistics and graphs.
Data Recipe app provides you a visual way to cleanse and prepare data for a model or some other task in a Pipeline. It also allows you to visualise data with EDA statistics and graphs.
Creating a Data Recipe
 You can create a data recipe by clicking on ‘Create New’ and providing the name and the optional description.
View list of recipe created along with their status and also preview a recipe DAG and it’s meta info.
You can create a data recipe by clicking on ‘Create New’ and providing the name and the optional description.
View list of recipe created along with their status and also preview a recipe DAG and it’s meta info.
Deleting a Data Recipe
Delete option in the data recipe options menu will delete the data recipe from the Project
Building a Data Recipe
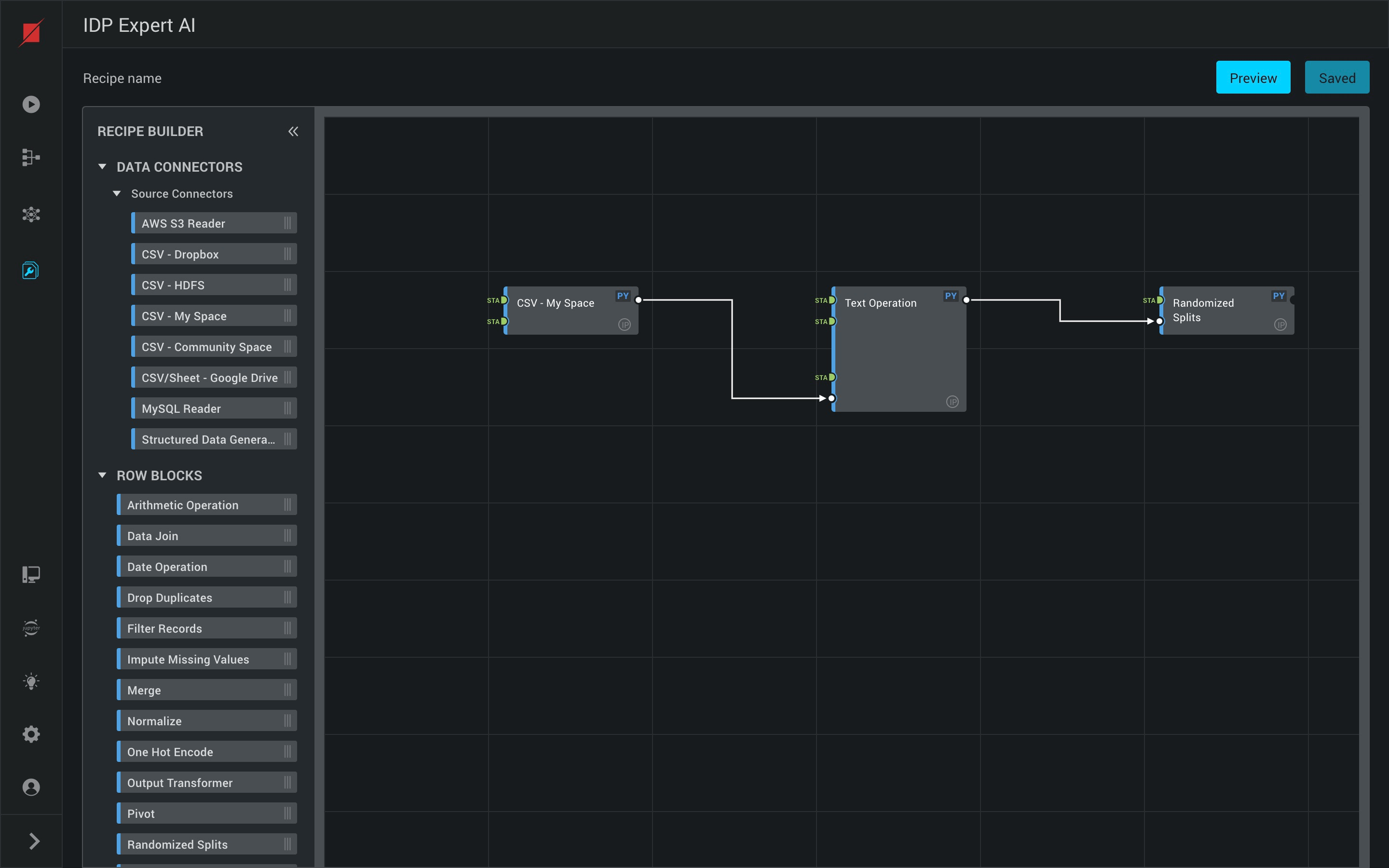
- Building a data recipe is as simple as dragging and dropping various Blocks from the left into the canvas and connecting them. Following are some of the types of Blocks available:
- Data Connectors:
- Source Connectors - Blocks to pull data from a source
- Target Connectors - Blocks to push data into a source
- Row Blocks
- Table Blocks
- Data Connectors:
- Aggregate Blocks
- Each recipe block can be configured with the required parameters in the right pane that you by clicking on the block.
Preview and Logs of your Data Recipe
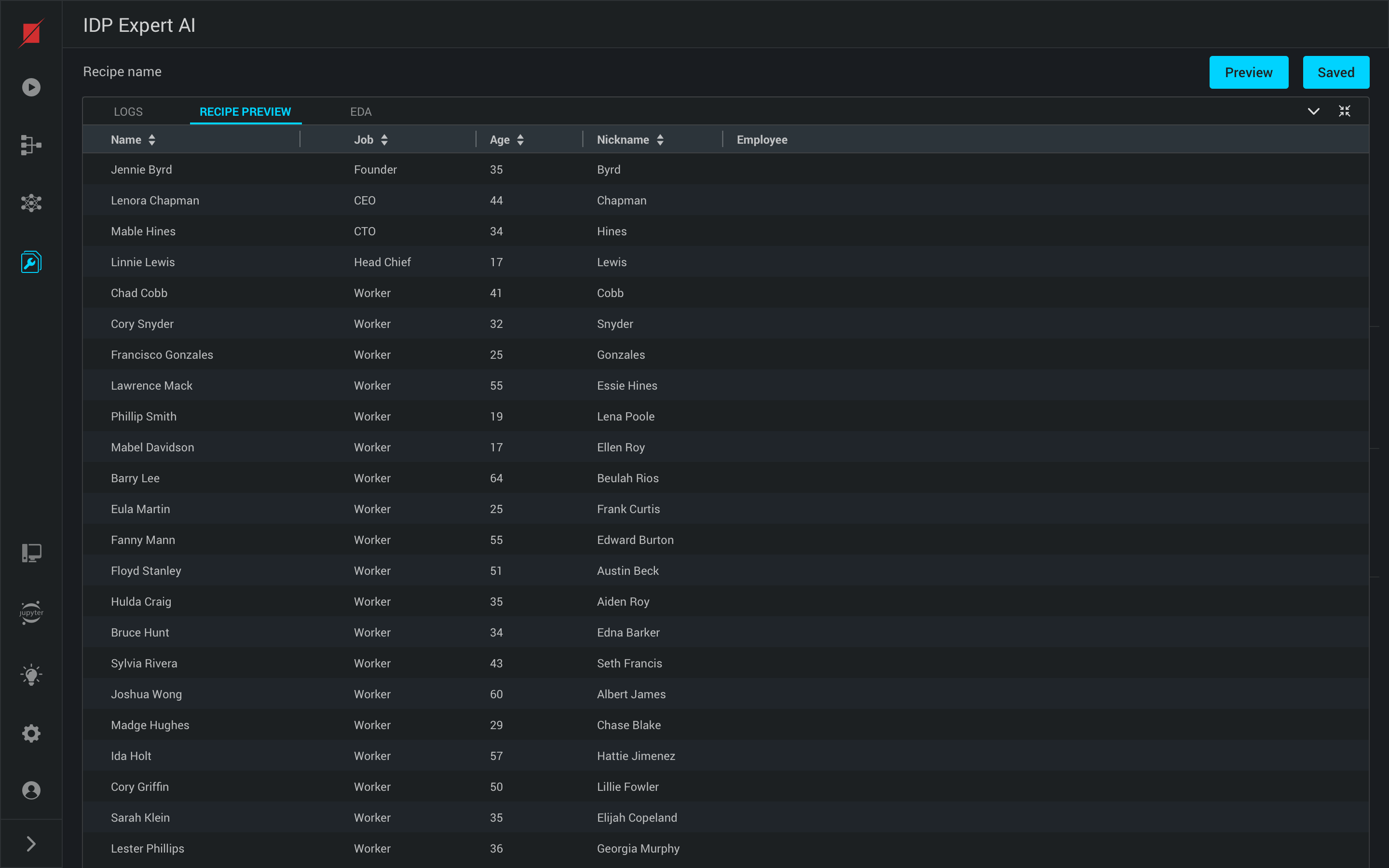 Clicking on the test button in the recipe builder, you can run the recipe on the source file and you can view the preview of the data after applying the data recipe in the preview section and its corresponding run logs in the Logs section
Clicking on the test button in the recipe builder, you can run the recipe on the source file and you can view the preview of the data after applying the data recipe in the preview section and its corresponding run logs in the Logs section
EDA on Source Data
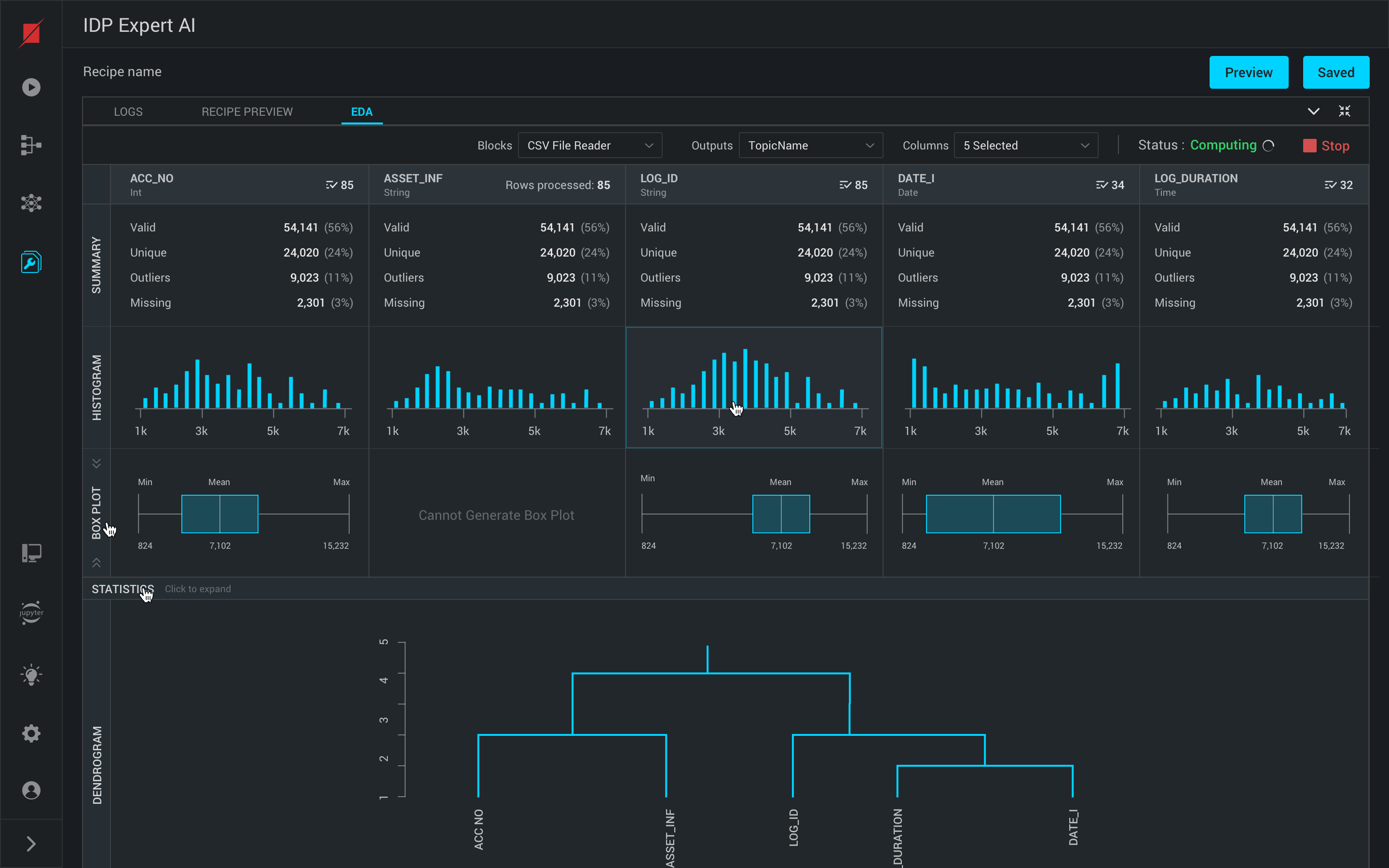 Platform provides you EDA on the data based on your source connector. On the EDA screen, select a few columns and click Start to generate EDA.
Platform will analyse your data and provide you a single view with graphical visualization of the complete data with a wide range of graphs like Histogram, Boxplot, Summary, Statistics, Dendrogram, Correlation matrix, scatter plot matrix.
Platform provides you EDA on the data based on your source connector. On the EDA screen, select a few columns and click Start to generate EDA.
Platform will analyse your data and provide you a single view with graphical visualization of the complete data with a wide range of graphs like Histogram, Boxplot, Summary, Statistics, Dendrogram, Correlation matrix, scatter plot matrix.
Creating a new Data Transformation Block
You can create a custom data transformation block for the data recipe by clicking on the “add” icon in the recipe builder and configure the new block by providing name of the block, technology used, category, Intellectual property status, code of the block and the following parameters input, input validation, output, handlers, resource requirement.
Editing custom Data Transformation Block
You can edit a custom block available in the recipe builder by using the edit block option and modify the structure and the configuration of the pipeline block.
Configuring Expressions for a Block Input
Expressions can also be given as inputs to some of the blocks, eg., Filter Block (used to filter column values based on expression given) or Arithmetic Block(used to perform arithmetic operations on input column values). These expressions are to be written using certain keywords.
row()
Returns the Index (Position of the row in the Data set) of the current row starting from 1.
For Text Operation block, Row Index will be returned in String format (StringType()) and for Arithmetic Operation block it will be returned in Integer format (IntegerType()).
Let's say, We have below Data set corresponding to Order Details of a Grocery Store
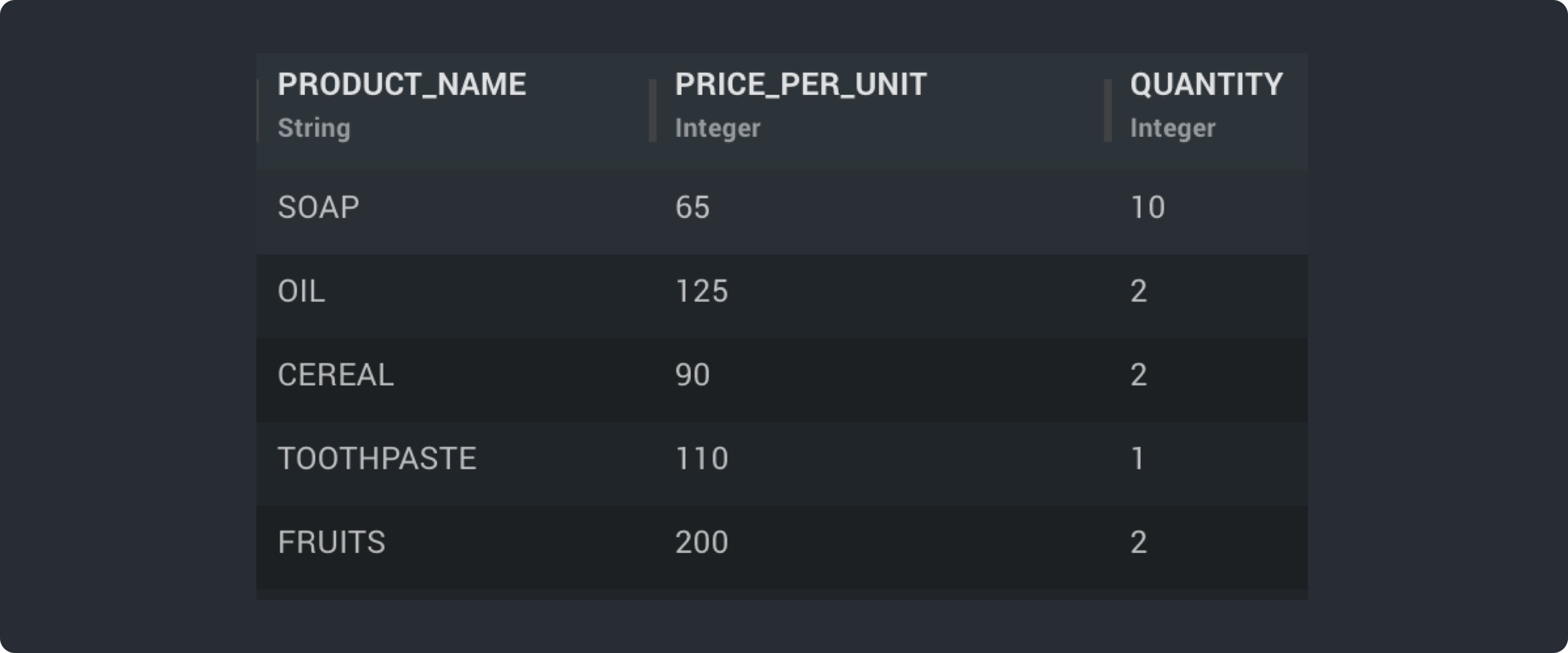
If we Use Expression as “row()” for above dataset and create a new column “Row Number” - Serial Number for each order using Arithmetic Expression Block then it will return below output
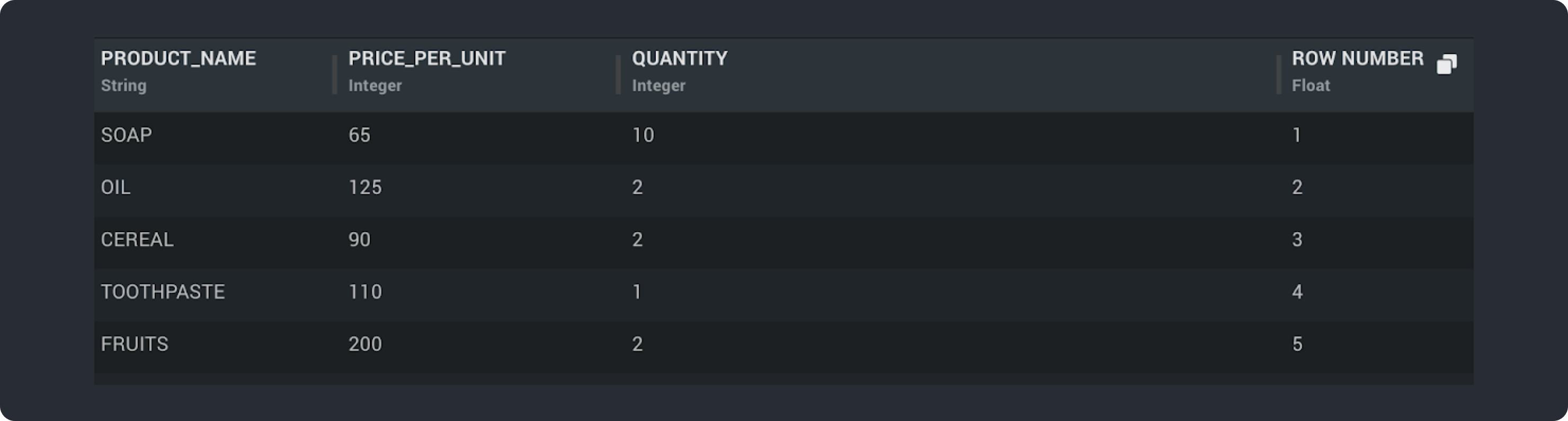
Eg: expression = ‘row() + 2’ #returns integer, if row() -> 3, then output = 5
expression = ‘row() + ‘abc’ #returns string, if row() -> 3, then output = ‘3abc’
column(‘<column_name>’)
Used to perform operations on values of given column ‘column_name’ in the current row.
Below example takes a Data set corresponding to order details of a Grocery Store and applies an expression to find “Total Cost” of each items.
Eg:
[
{
"outputColumn": "Total Cost",
"outputType": "FLOAT",
"onErrorDefaultValue": 0,
"expression": "column('PRICE_PER_UNIT')*column('QUANTITY')"
}
]
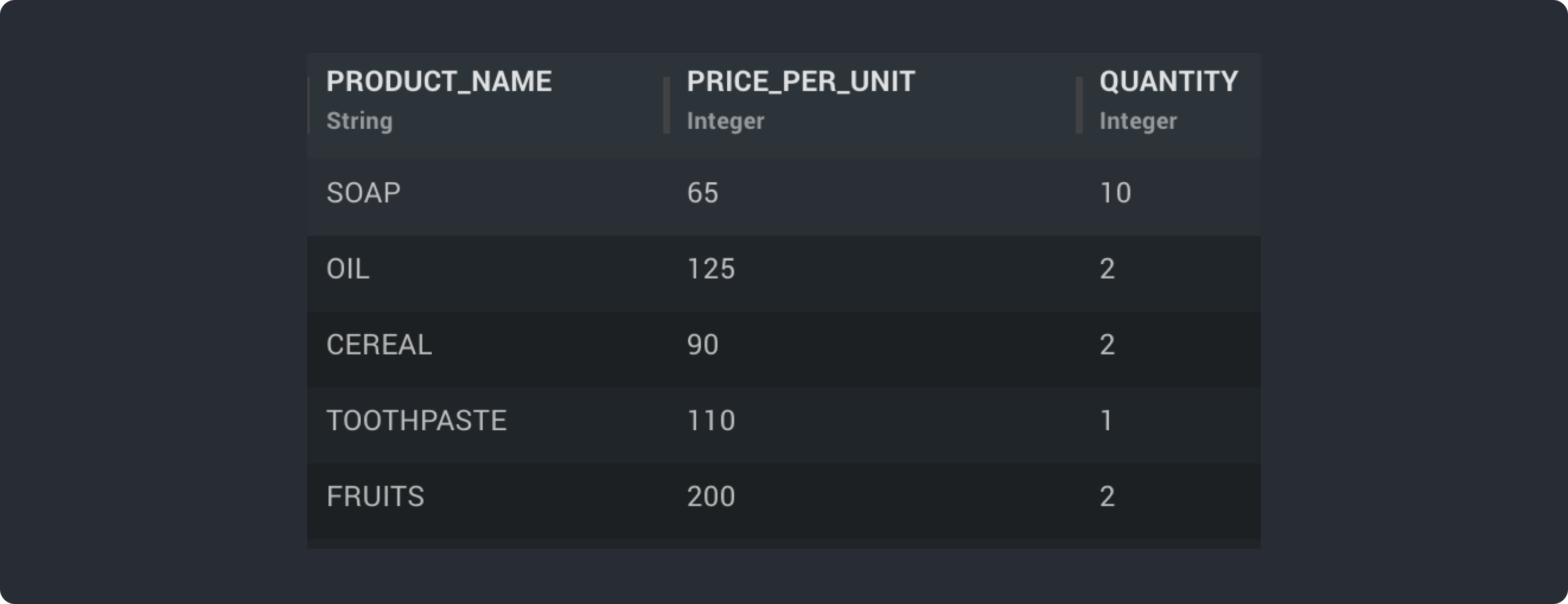
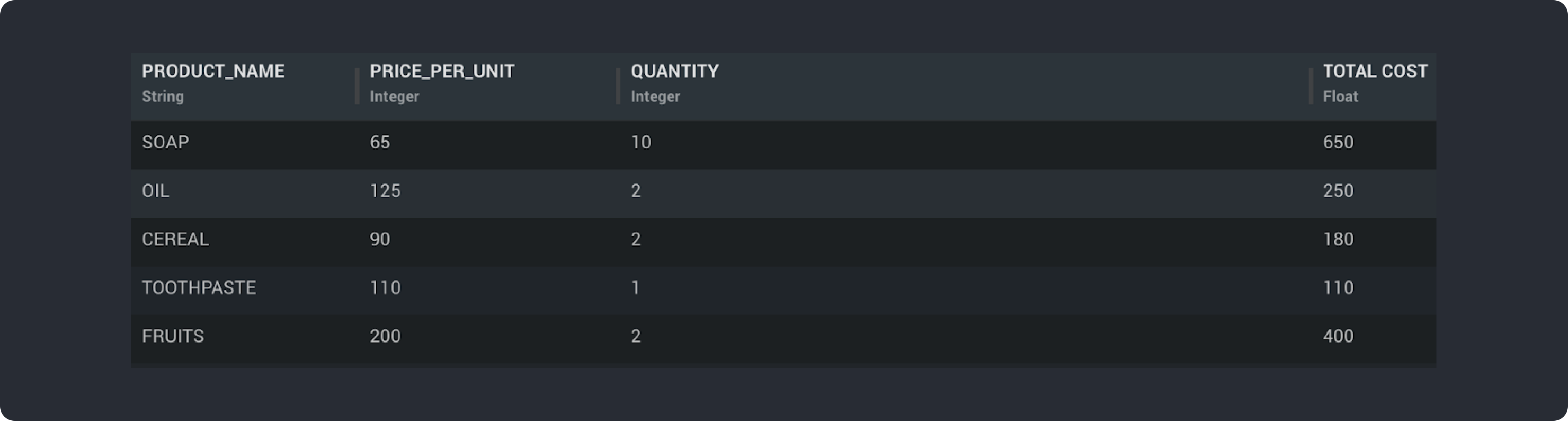
key()
Gives the value of a key in the map or dictionary specified in “Constants” input of the Block.
This can be used to map JSON output of Aggregate Blocks to “Constants” input of Expression Block and use the aggregates values in the Current Block.
Eg:
"Constants": {
"test": {"temp": 100},
"aggregate": {"count": {"id": 10 }},
"random": 10
}
expression = key(‘Constants.aggregate.count.id’) # returns value 10
expression = column(‘ID’) > key(‘Constants.aggregate.count.id’)